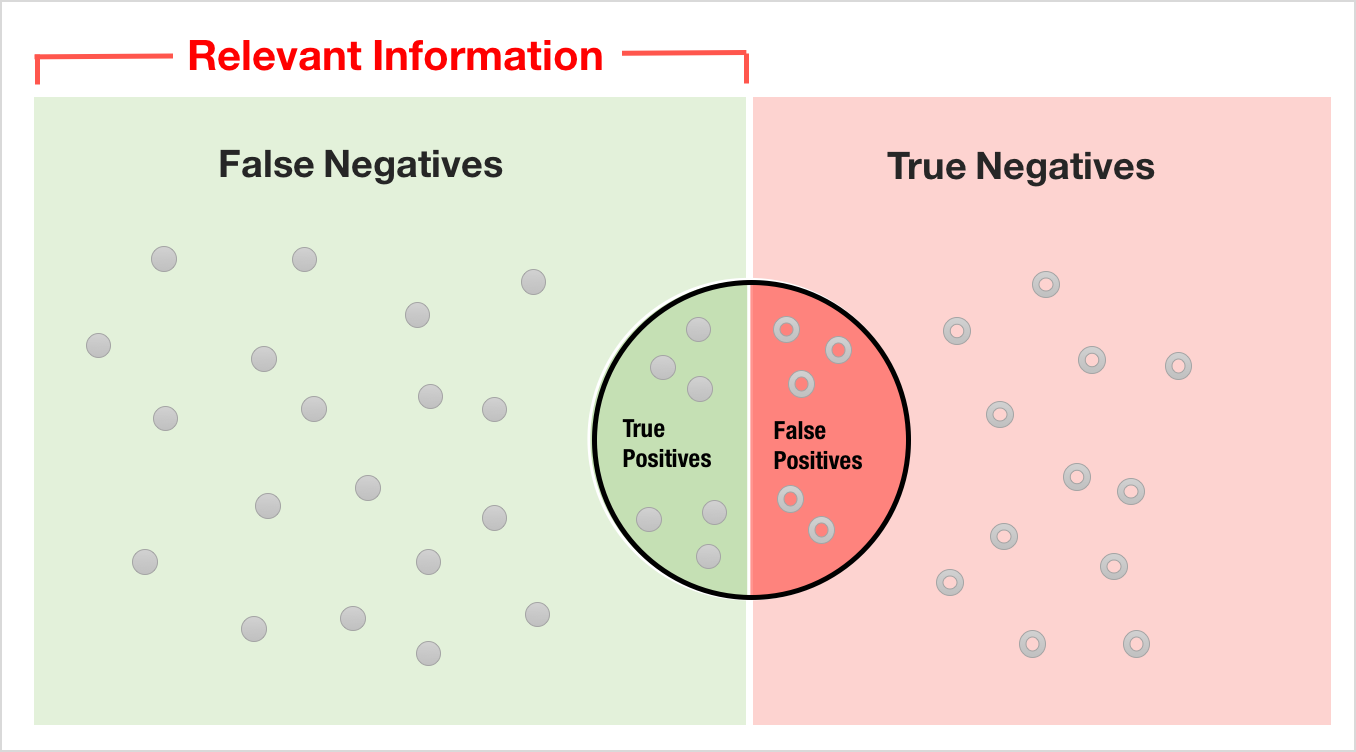
True Positive (TP)
True positive (TP) is an outcome where the model correctly predicts the positive class for a binary target variable.
True positive (TP) is an outcome where the model correctly predicts the positive class for a binary target variable.
True negative (TN) is an outcome where the model correctly predicts the negative class for a binary target variable.
Tree diagrams may represent a series of independent events, such as a set of coin flips or conditional probabilities such as drawing cards from a deck, without replacing the cards. Each node on the diagram represents an event and is associated with the probability of that event. The root node represents the certain event and […]
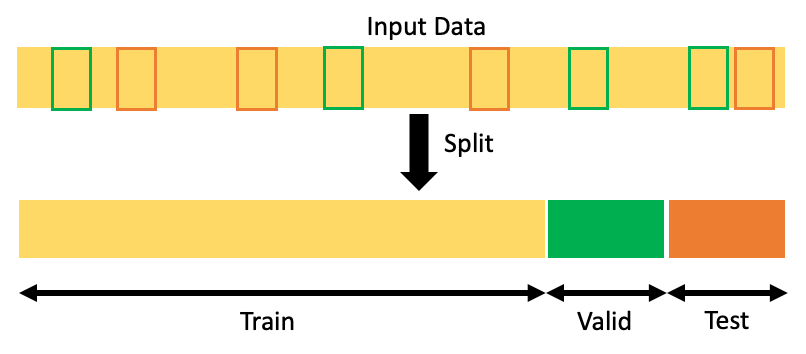
A training set is a subset, or a part of the available data isolated before building a model, usually from 70 to 80% of the entire dataset. A training set is used for fitting the model that will later be tested on the test set.
A time series is a sequence of observations of a variable taken at different times and sorted in time order. Usually, time series measurements are taken at successive, equally spaced points in time. Some examples of time series are stock market prices or the temperature over a certain period of time.
A test set is a subset, a part of the available data isolated before building a model, usually between 20 to 30% of the entire dataset. Test sets are used for evaluating the accuracy of models fitted on a training set.
TensorFlow is an open source framework for machine learning. It has a myriad of tools, libraries, and community resources that lets developers easily build and deploy ML-powered applications, and researchers innovate in ML. It can be used across a range of tasks, but is particularly focused on training and inference of deep neural networks.
A target variable (also called dependent variable) is the variable to be predicted in a machine learning algorithm by using features, for example if we’re predicting likelihood of diabetes using height, weight, and sugar intake, diabetes status is the target variable we want to predict.
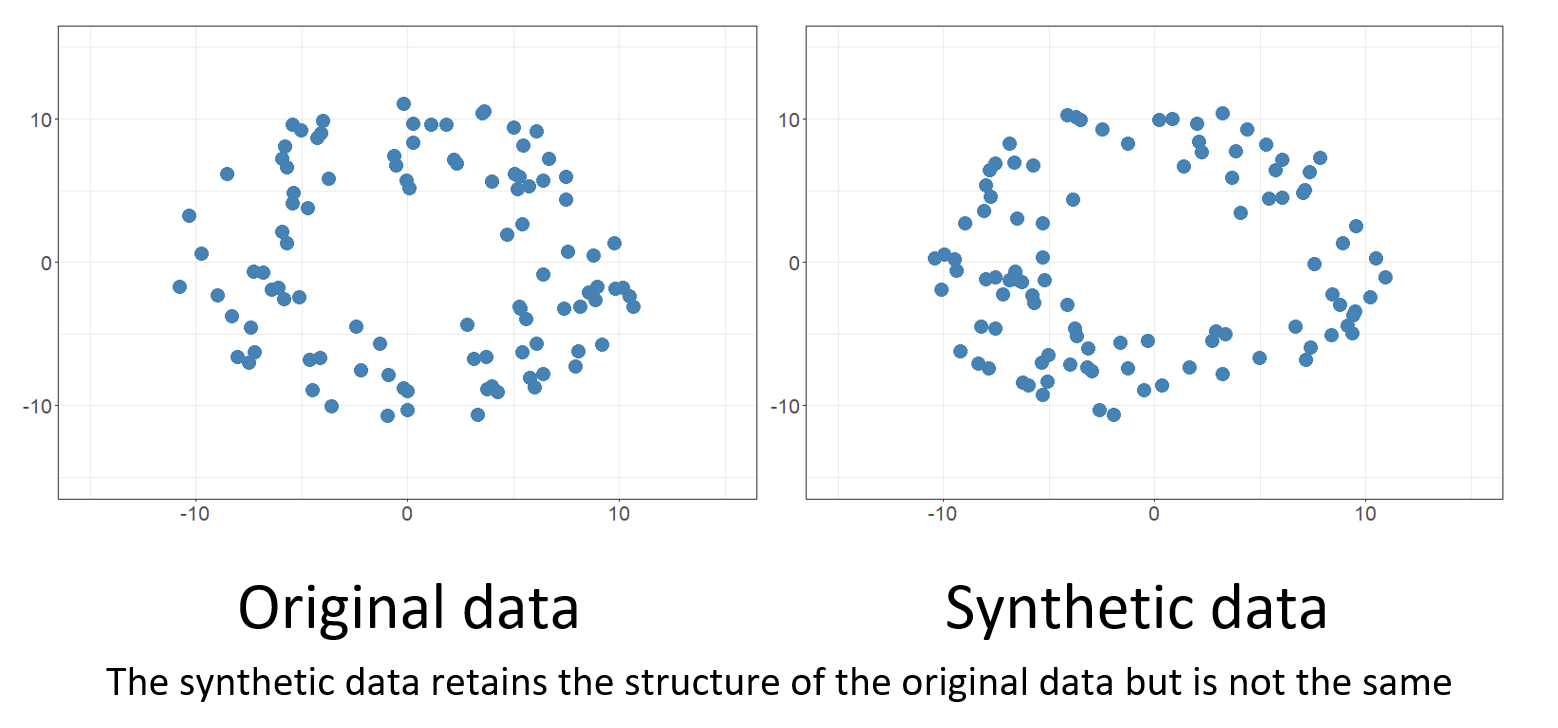
Synthetic data is artificially created data. Synthetic data usually reflects the statistical properties of the initial dataset, so they can be used in high-privacy spheres such as banking and healthcare, or for augmenting an existing dataset with additional statistically representative data observations.
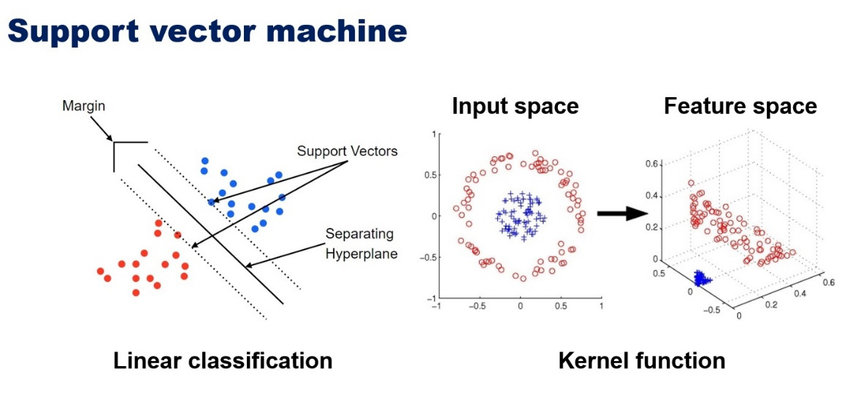
SVM (Support Vector Machine) is a supervised learning algorithm used mostly for classification, but also regression problems. In a classification problem, SVM provides an optimal hyperplane that separates the observations of both classes, in the case of a multiclass classification, the algorithm breaks down the problem into a set of binary problems. In a regression […]