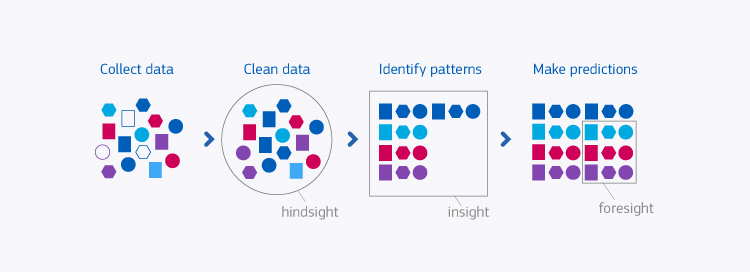
Data wrangling, sometimes referred to as Data Munging, is the process of manipulating raw data into a format that is more appropriate and useful for further analysis. It involves cleaning up data by removing or modifying incorrect data points, normalizing or standardizing formats, transforming data into different forms that are more suitable for analysis, and using various techniques to merge disparate datasets.
Data wrangling is an essential step in any modern data analytics pipeline; it ensures that the generated datasets are accurate, consistent and easily interpretable by downstream tools and applications.
Goal of Data Wrangling
The goal of data wrangling is to transform raw datasets into a structured form so that it can be used effectively for further analysis. This process usually involves identifying patterns and trends in the source data, understanding its structure and content, transforming it to a new form and then introducing additional fields or columns as necessary.
Data cleaning operations such as correcting errors, missing values, outlier removal also play an important role in making sure the dataset is valid for further analysis. Additionally, during the wrangling stage additional features can be derived from existing variables with proper transformation techniques such as binning or clustering.
Preparation of Datasets
Finally, some basic exploratory analysis can be performed before moving onto the next steps of predictive modelling or machine learning tasks. Data wrangling provides an opportunity to properly prepare datasets so they can be utilized in various applications like machine learning algorithms or statistical models.
Extraction of Useful Information
It allows us to extract useful information from large amounts of raw information by preparing it for specific tasks. Furthermore, it helps make sense of complex relationships between variables which can help researchers gain better insight into their subject matter. Ultimately, through proper data wrangling strategies organizations can create insights out of their available resources faster and cheaper than ever before.
Data wrangling is a crucial step in the data science process that involves cleaning and organizing raw data before performing analysis. There are several advantages and disadvantages associated with data wrangling that need to be considered.
Advantages
- Improved Data Quality: By cleaning the data, data wrangling reduces errors and inconsistencies, improving the data quality. This ensures that the data is more reliable and accurate.
- Enables Better Decision Making: High-quality data is critical for making informed decisions. Data wrangling ensures that data is organized, structured, and formatted in a way that enables better decision making.
- Saves Time and Effort: Data wrangling automates the process of cleaning and organizing data, saving time and effort. It also reduces the risk of errors that would otherwise require manual correction.
Disadvantages
- Requires Expertise: Data wrangling requires knowledge of statistics, programming, and data analysis. It can be challenging for non-experts to perform the data wrangling process effectively.
- Time-Consuming: Data wrangling can be a time-consuming process, particularly when dealing with large volumes of data, and can delay the analysis process.
- Data Loss: Data wrangling can result in the loss of data if it is not done correctly. This could negatively impact the analysis process and lead to incorrect conclusions.
Conclusion
In conclusion, data wrangling is crucial for obtaining high-quality, reliable data for analysis. While it has several advantages, it also requires expertise and can be time-consuming. Organizations must weigh these factors and determine whether data wrangling is suitable for their data analysis needs.